In this project, we address a key issue with current state-of-the-art 6-DoF pose estimation networks by contextualizing object parts which in turn provides more suitable grasp locations for robotic manipulation.
Ultimately, we integrate an object-based affordance detection network with a 6-DoF pose estimation network. That is, we modify open source work written in PyTorch, to have a framework similar to AffordanceNet and adapt DenseFusion to train on our dataset. From a literature review, we believe no such existing benchmark dataset contains both ground truth affordance labels and 6-Dof pose. This serves as our main motivation for creating our dataset to ultimately deploy our trained models in real setting for grasping experiments with objects of interest.
Traditional dataset with 6-DoF pose defined to object's centroids.


Proposed dataset with 6-DoF pose defined to the most suitable affordance for grasping.


The main contributions of this work is the creation of our dataset which contains over 100k real and synthetic images with 11 different household objects and 9 different affordance labels. We also present our results for experiments evaluating 6-DoF pose estimation with traditional object segmentation versus object-based affordance detection.
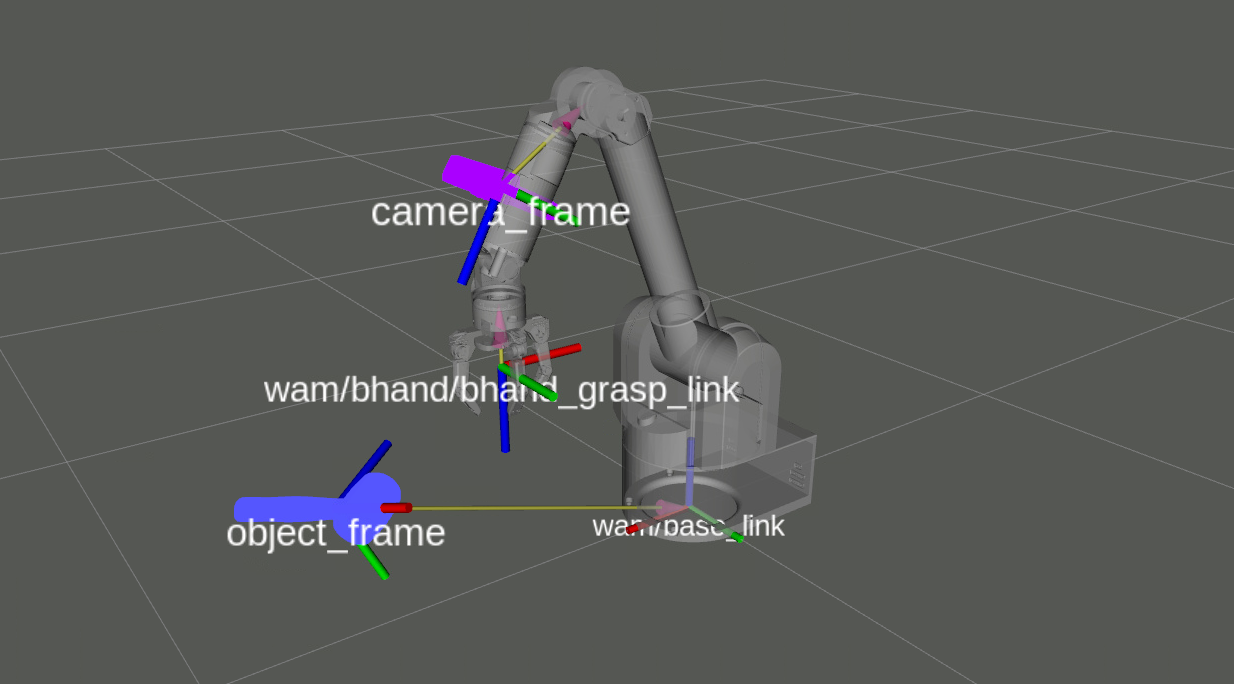
A ROS node was later developed to test real-time implementation the proposed pipeline. In this work it is important to understand how an object pose can be used for robotic grasping. 6-DoF pose estimation frameworks, such as DenseFusion, compute the object's pose w.r.t the camera frame. However, to grasp an object, we need the 6-DoF pose of the object w.r.t the base link frame of a manipulator.
This work will soon be published!